

Frisch-Waugh Theorem
Assume that we have a regression model with \(\small{ k }\) different variables. In some cases, we might not be interested in all \(\small{ k }\) variables, but in a subset only.
\[y=X\beta+Z\gamma+\varepsilon\]
The theorem uses a projection matrix \(\small{ P=Z^\prime\left(Z^\prime Z\right)^{-1}Z^\prime }\) so that \(\small{ Q=\left(I-P\right)}\). Now, \(\small{ Q }\) is the orthogonal projection onto the column space of \(\small{ Z }\) and therefore eliminates the influence of \(\small{ Z }\).
\[y=X\beta+Z\gamma+\varepsilon \\ \Leftrightarrow\ X^\prime Qy =X^\prime QX\beta+X^\prime QZ\gamma \\ \Leftrightarrow\ X^\prime Qy =\ X^\prime QX\beta \\ \Leftrightarrow\hat{\beta} =\left(X^\prime Q\ X\right)^{-1}\ X^\prime Qy\]
After this transformation, we have our model \(\small{ Qy=QX\beta+Q\varepsilon }\) with the variance \(\small{ \mathbb{V}\left(\hat{\beta}\right)=\sigma^2\left(X^\prime Q\ X\right)^{-1} }\) .
The vectors of the OLS residuals \(\small{ \varepsilon_0=y-(X\hat{\beta}+Z\hat{\gamma}) }\) and \(\small{ \varepsilon_{FW}=Qy-QX\hat{\beta} }\) coincide.
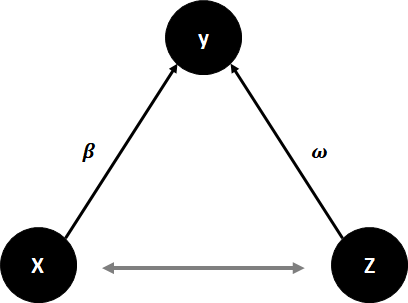
By eliminating \(\small{ Z }\) with Frisch-Waugh, we still capture the effect of \(\small{ Z }\) but without including the additional variables in our model.
Model Misspecification
We call a model misspecified if we discover over- or underspecification. Let’s have a quick look at the difference:
| Overspecification | Underspecification |
| True Model: \[y=X\beta+\varepsilon\] Estimated Model: \[y=X\beta+Z\omega+\varepsilon\] Problem: Overspecification is not a big problem, but the estimation will lose some efficiency. | True Model: \[y=X\beta+Z\omega+\varepsilon\] Estimated Model: \[y=X\beta+\varepsilon\] Problem: Underspecification is a severe problem, since our estimated coefficients are incorrect. |
The F-test provides a test statistic to identify model misspecification. Let there be two different regression models \(\small{ m0_{N\times K}:\ y=X\beta+\varepsilon }\) and \(\small{ m1_{N\times L}:\ y=X\beta+Z\omega+\varepsilon }\). We assume that \(\small{ m1 }\) is the true model and formulate the hypotheses
\[H_0:\ \omega=0\] or \[H_1:\ \omega\neq0\]
We now calculate the F-statistic, with \(\small{ N-K-L }\) degrees of freedom, where \(\small{ N }\) is the number of rows, and \(\small{ K+L }\) denote the number of columns.
\[F\left(m\right)=\frac{(RSS\left(m0\right)-RSS\left(m1\right))/L}{RSS(m1)/(N-K-L)\ \ }\]
The null hypothesis \(\small{ H0 }\) is rejected at level of significance \(\small{ \alpha }\) , if \(\small{ F\left(m\right)>F_{L,\ \ \ \left[N-K-L\right]}^{1-\alpha} }\) holds.
Bias: Correlation and Underspecification
Let’s assume that two regressors \(\small{ \beta_1 }\) and \(\small{ \omega_0 }\) are positively correlated in our model
\[y_i=\beta_0+\beta_1x_i+\omega_0z_i+\varepsilon_i\]
If we now build our regression model without \(\small{ \omega_0 }\) , then \(\small{ {\hat{\beta}}_1 }\) will measure the effect of \(\small{ \omega_0 }\) on \(\small{ y_i }\) and will not be unbiased.
\[Bias\left({\hat{\beta}}_1\right)=\mathbb{E}\left[{\hat{\beta}}_1\right]-\beta_1=\frac{corr(x,z)}{Var(x)}\omega_0\]
If both regressors are positively correlated (and \(\small{ \omega_0>0 }\) ), we expect a positive bias.